How to Keep Your Machine Learning Data Confidential
The year was 1997. Latanya Sweeney was a graduate student in the MIT computer science department. Her claim to fame? Correctly identifying the Governor’s health records from an anonymous insurance record database. ...

The year was 1997. Latanya Sweeney was a graduate student in the MIT computer science department. Her claim to fame? Correctly identifying the Governor’s health records from an anonymous insurance record database.
Sweeney had solved the problem of re-identification using Machine Learning. The solution involved matching anonymous data with publicly available information, or auxiliary data, in order to discover who the data belonged to. She is now a Professor of the Practice of Government and Technology at Harvard University.
Preserving data confidentiality is mission-critical in every sector. Whether it’s identifying Netflix users using the Internet Movie Database (IMDB), or researchers re-identifying 99.8% of individuals using only 15 demographic attributes, the benefit to organizations is evident.
The less clear question answered in this article is how can data be kept confidential whilst developing machine learning models?
The Risks of the Machine Learning Process
Data is extracted from its “native” environment and copied elsewhere in an unencrypted form during the training of Machine Learning models.
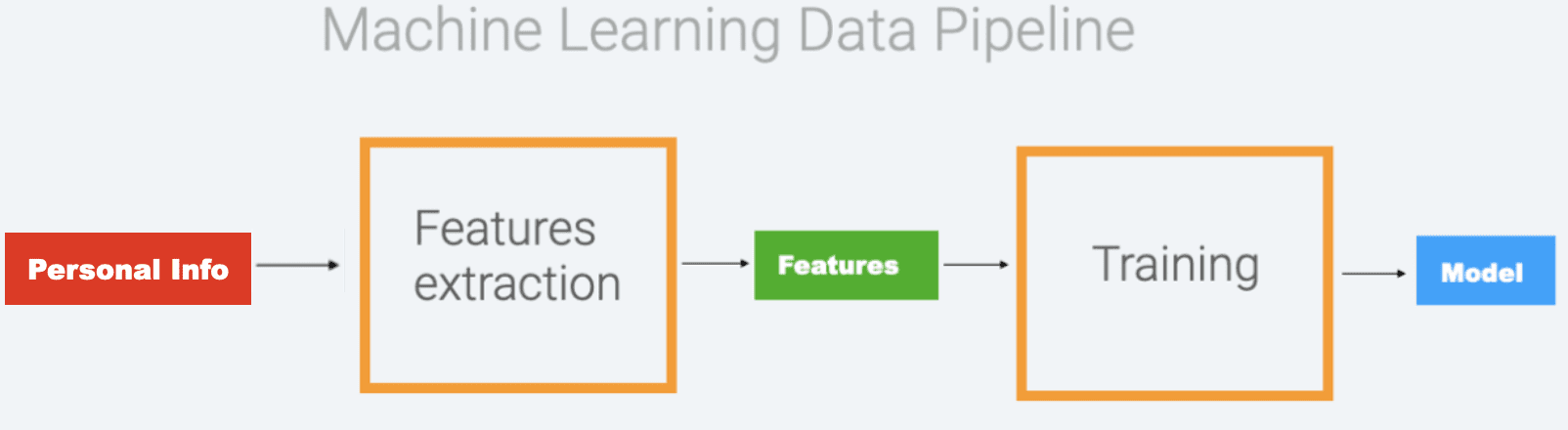
Data processing occurs in a two-step pipeline:
- Transform raw data into “signatures” (attributes) – (e.g. raw data: age of client 64, attribute: “senior”, from the numerical value – raw data, we extract a categorical attribute or signature “senior)
- Use these attributes to create a statistical model
The machine learning data pipeline model encapsulates all the knowledge and patterns hidden in the raw input data.
Addressing the following risks is key in keeping data confidential:
- Data leaks before feature extraction
- De-anonymization of publicly shared data
- Decryption of features
Step 1: Data due diligence
The first step in securing your machine learning pipeline is assessing how confidential the data is. This involves identifying the Personal data (PI) in the data set to be used for your machine learning initiative. This data, or personal information, consists of information which either:
- Directly distinguishes or traces an individual’s identity (e.g. name, social security number, biometric records, etc.)
- Links to an individuals’ identity when combined with other identifying information, (e.g. data and place of birth, mothers maiden name, etc.)
Step 2: Secure your Data Set
Once you have identified Personal Information data, you have two options:
- Remove PI data prior to training. This is the easy option. By omitting the personal information from your data set you will avoid several challenges relating to the security and retention of data.
- Use strong encryption to maintain the predictive power of Personal Data in your machine learning. Specific domains like healthcare and social media networks have developed such techniques.
Step 3: Secure your Machine Learning Pipeline
The last action is to retain control of your data after you feed it to your pipeline. To do that, recent advances in Machine Learning are helpful.
In particular, a new technique called Federated Learning. The intuition behind Federated Learning is very simple: your data is securely stored and doesn’t move, and only a secure and encrypted version of it is passed to the Machine Learning algorithm!
The main benefit of this approach is a secure data pipeline by-design.
Conclusion
Keeping your data confidential when training machine learning models is like many other situations, the right start makes all the difference. Understanding the highlighted risks and following the steps detailed will allow you to reap the rewards from applying Machine Learning to your data.
For more queries and concerns on keeping your machine learning data confidential, why not book in for a free A.I & Machine Learning clinic and consult with an expert.