Introduction to Automated Machine Learning
Introduction to Automated Machine Learning Automated Machine Learning represents a fundamental shift in the way companies and organizations approach Machine Learning and data science. Applying traditional machine learnin...
Introduction to Automated Machine Learning
Automated Machine Learning represents a fundamental shift in the way companies and organizations approach Machine Learning and data science.
Applying traditional machine learning methods to real-world business problems is time-consuming. It requires a lot of resources, and a bunch of experts in several disciplines including data scientists with excellent computer science skills. Moreover, building a machine learning system is always a challenge: you need to design experiments, run them, and analyze the results, until, after repetitive failures, you start improving. You can also get underwhelming results. That’s why it is very important to take careful considerations before embarking on a broad and long-running project.
But Automated Machine Learning can be the turning point to overcome most of these annoying issues. It directly responds to the high demand for accelerating the time required to obtain off-the-shelf machine learning models that can be used easily and without expert knowledge.
What is Automated Machine Learning?
Automated Machine Learning (AutoML) is the process of automating repetitive and time-consuming tasks associated with developing Machine Learning models. It enables data scientists, analysts, and developers to create machine learning models with high scalability, efficiency and productivity. All the while ensuring high-quality models. The high degree of automation in AutoML allows even non-experts to make use of machine learning models without requiring them to become specialists in the sector. The automation of tedious ML-related tasks then lets ML teams focus on high level problems that require their expertise. In this way, organizations can rely on a decentralized process, open to all users, and nurtured by up-to-date knowledge.
Comparison to the standard approach
So, what is the difference between automated and traditional machine learning?
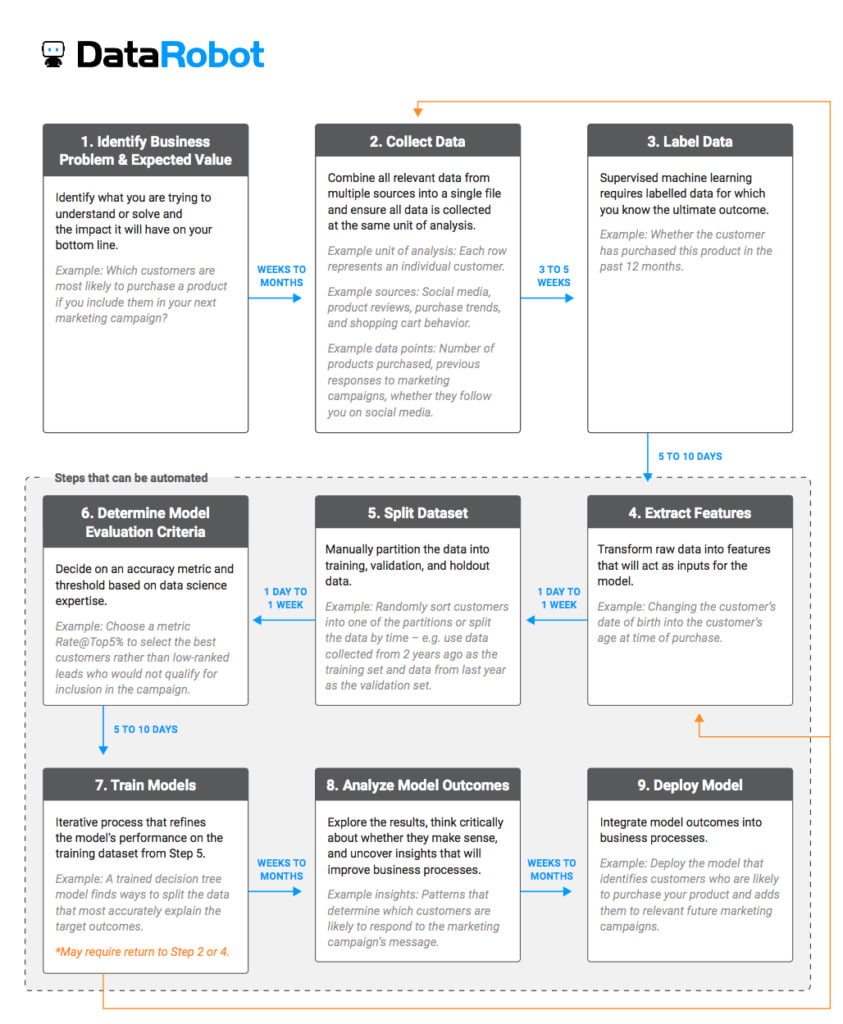
In a typical machine learning deployment, you need to take the following steps (as described in the Figure 1):
- Identify the business problem and consider the value untapped and the costs related to the deployment (cost-opportunity analysis). It can take several months before a company decides to start the ML project and it often requires the involvement of the highest senior management.
- Collect data: gather all the data that a company has accumulated in many years and make them at the same unit to be analyzed. It is not as easy as pie!
- Label data: distinguish and manually assign labels to a great amount of data so that a machine learning model can learn from it. It’s a repetitive monotonous task,often outsourced and sometimes it lacks accuracy.
- Extract features: from raw data derive features, intended to be informative, to facilitate the subsequent learning.
- Split Data set: take the data set and divide it into two or more subsets to evaluate the performance of the machine learning algorithm.
- Determine model evaluation criteria: that means decide the metric and the threshold for the accuracy measure.
- Train models: repetitive train process to improve the model at every stage.
- Analyze model outcomes: explore the results and think if they really can create a new business value.
- Deploy model: finally integrate the model into business processes.
Developing a model with the traditional approach implies covering all the steps. In fact, only the step of model training is an automatic task. Thanks to Automated Machine Learning it is possible to automate many more steps, those outlined in red in Figure 1.
Courtesy of DataRobot:
When to use AutoML: classification, regression & forecast
Automated machine learning democratizes the machine learning model development process, allowing non-experts to develop a ML pipeline. But what are the ML models that can be automated?
Classification
Classification is one of them. It is a type of supervised learning in which models learn from a training data set how to estimate the classification of new data into categories. The common use cases of classification models are those of object detection or also fraud detection, to name a few.
Regression
Similar to classification, also regression models can be automated. They are supervised learning activities in which models estimate numerical output values based on independent predictors, or variables. For example, the cost of a T-shirt is based on characteristics such as the periodic sales amount, the color etc.
Time series prediction
Making accurate predictions is important for many business activities, from revenue to sales predictions. The great news is that developing a prediction model can be automated. A time series model is considered a multivariate regression model. The values from the previous time series are “pivoted” to become additional dimensions for the regression along with other predictors. The more data is available for estimating the model parameters, the more accurate the prediction model will be.
Conclusion
Recently, the attention on Federated Learning has increased exponentially, as many companies have noticed its great potential. Not only does it give access also to non-experts to ML pipeline management tasks, but it permits big organizations to save time and resources, providing effective solutions to problems.