Preparing Audio Data for a Custom Machine Learning Model
AI is improving processes across the board for businesses measuring sound. Smart companies in this sector are already integrating off-the-shelf solutions into their business. Certain companies may find, however, they hav...

AI is improving processes across the board for businesses measuring sound. Smart companies in this sector are already integrating off-the-shelf solutions into their business. Certain companies may find, however, they have specific data requirements. This means off-the-shelf models simply won’t work. The solution? A custom machine-learning model. In this guide, we will explore how you can effectively collect and prepare your specific data for the development of a tailored AI model. By following these steps, you’ll be equipped to leverage the full potential of AI in sound recognition.
Step 1: Define the Problem
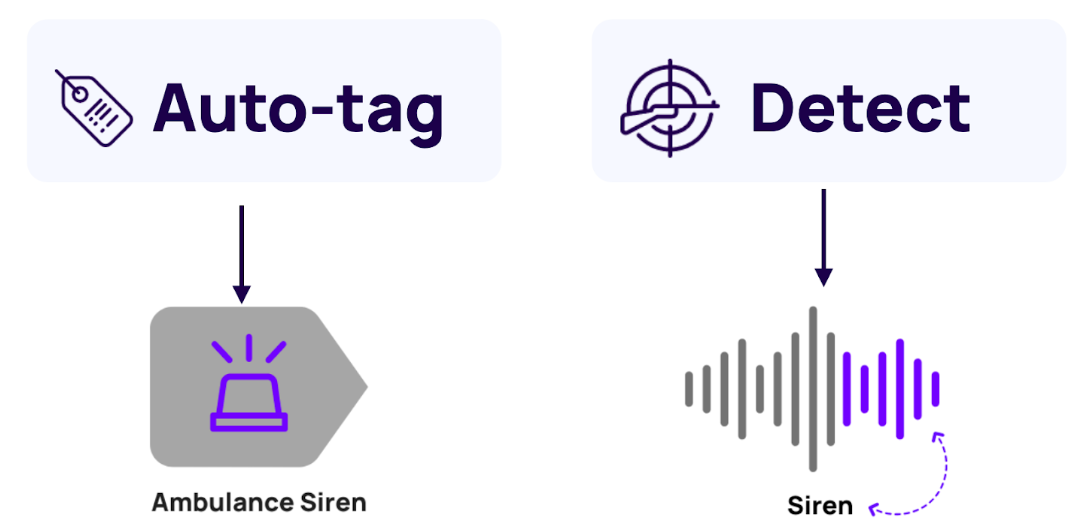
Step 2: Collect and Prepare the Data
Gather the Data
Consider the Context
Step 3: Train the Machine Learning Model
Conversion
Segmentation
Normalisation
Feature Extraction
Step 4: Label the Data
Each of your audio samples needs to be labelled with its corresponding outcome or label. This is a critical step, as it’s this labelled data that your model will learn from. The labels will depend on the problem you’re trying to solve – if you’re identifying construction sounds for example, each label might be the names of different equipment.
- Annotation Design: Design an annotation scheme that defines the specific sound categories you want the model to recognise. For example, your annotation scheme may include labels like “engine revving,” “glass breaking,” “tyres screeching,” etc.
- Manual Labelling: If your data is unlabelled, it’s necessary to manually attach labels. This provides the machine-learning model with a data bank. With these manual annotations, the AI will use auto-machine learning to automatically assign these labels in the future.
- Quality Assurance: Implement quality assurance measures to ensure accurate annotations. Perform regular checks and inter-annotator agreement assessments to evaluate consistency. Resolve any discrepancies or ambiguities through discussions or clarifications.
Once you’ve defined your problem, collected and prepared your data, and labelled it accurately, we can move on to the next step: training your custom machine learning model.
Final Thoughts
Data is the lifeblood of machine learning. It forms the bedrock of our endeavours, enabling our models to thrive. While off-the-shelf solutions have their merits, companies that follow the steps outlined in this guide can effectively collect and prepare unique data to develop tailored AI models. By doing so, they can fully leverage the power of AI, achieve greater accuracy, make informed decisions, optimise processes, and gain a competitive advantage in the market. Embracing custom models opens up new possibilities for innovation and expansion, ensuring businesses stay ahead in the evolving landscape of sound measurement.